

Why optimising robots.txt is so important for you
A prevalent issue I see among many websites lies in the indexing of numerous single pages hosting minimal or poor quality content
Consider author or category archives within your blog, internal search result pages, or dynamically generated pages through product filters in an online store.
This practice often results in the indexing of thousands of disparate, low-quality pages, adversely impacting the overall website quality.
It’s a simple equation: the greater the presence of low-quality content, the poorer your website’s ranking.
Avoiding this scenario is crucial for maintaining strong rankings and overall site quality.
Understanding robots.txt
As a website owner, it is crucial to have a good understanding of your website’s robots.txt file.
This file plays a significant role in determining how search engines crawl and index your site. The robots.txt file acts as a set of instructions for search engine robots, informing them which pages they can and cannot access.
By properly configuring your robots.txt file, you can have more control over the visibility and accessibility of your website.
When a search engine robot visits your website, it first looks for the robots.txt file in the root directory.
It then reads the instructions and follows them accordingly. By using the robots.txt file, you can block certain pages or directories from being indexed by search engines. This is helpful when you have specific pages that you want to keep hidden from search engine results.
If you are unsure whether your website has a robots.txt file or if it is properly configured, you can use the robots.txt tester tool in Google Search Console to check. This tool allows you to test and validate your robots.txt file, ensuring that it is correctly set up and working as intended.
Importance of robots.txt
The robots.txt file plays a crucial role in the technical SEO of your website. It helps search engines understand which pages to crawl and index, ensuring that your site is properly optimised for organic search. Here are some key reasons why robots.txt is important:
1. Improved crawl efficiency
2. Protection of private content
If you have certain pages on your website that should not be accessible to the public, such as admin or login pages, robots.txt can be used to block search engine bots from accessing those pages. This helps protect sensitive information and enhances the security of your website.
3. Better indexing control
By specifying which pages should not be indexed, you can ensure that search engines do not display irrelevant or low-quality content in their search results. This helps maintain the quality and relevance of your website’s indexation.
Where to find and edit robots.txt file in WordPress?
If you do not want to touch the files on your server, which I recommend not doing in the beginning, then download the SEO plugin from YOAST via your wordpress plugin dashboard and navigate through the following steps:
Step 1: Go to YOAST SEO >> Tools

Step 2: Click on File editor
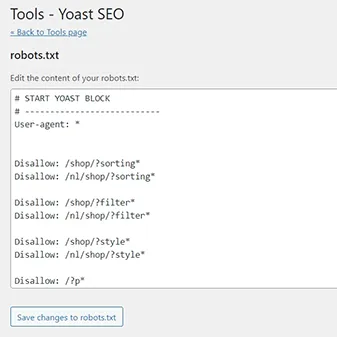
Step 3: Find and edit robots.txt file
Creating an effective robots.txt file
1. Identify pages to be blocked
Before creating your robots.txt file, identify the pages or directories on your website that you want to block from search engine crawlers. These may include pages with sensitive information, duplicate content, or staging sites that are not ready for public access.
2. Use the correct syntax
The robots.txt file follows a specific syntax. Each directive consists of the “User-agent” field, which specifies the search engine bot, and the “Disallow” field, which indicates the pages or directories that should be blocked.
Use the correct syntax to ensure that the robots.txt file is correctly interpreted by search engines.
Here’s an example:
User-agent: *
Disallow: /blocked-page/
You will find many useful robots.txt rules on the Google Search Central Robots.txt documentation.
3. Test your robots.txt file
After creating your robots.txt file, it is essential to test it using the “robots.txt tester” tool in Google Search Console. This tool helps you identify any issues or errors in your file that may prevent search engine bots from accessing your website properly.
4. Regularly update your robots.txt file
As your website evolves, you may need to update your robots.txt file. Make sure to review and update it regularly to reflect any changes in your website’s structure or content.
Common mistakes to avoid
When optimising your robots.txt file, it is essential to avoid common mistakes that can prevent search engines from properly crawling and indexing your website. Here are some common mistakes to avoid:
- Blocking important pages: Be cautious when specifying which pages or directories to block. Blocking important pages, such as category pages or product pages, can prevent search engines from indexing and displaying them in search results.
- Incorrect syntax: Using incorrect syntax in your robots.txt file can render it ineffective or even block search engine bots from accessing your entire website. Make sure to double-check your syntax and use the correct format.
- Disallowing CSS or JavaScript files: Blocking CSS or JavaScript files in your robots.txt file can negatively impact your website’s performance and user experience. Avoid disallowing these files to ensure proper rendering and functionality.
Optimising your robots.txt file for technical SEO is crucial for improving your website’s visibility and search engine rankings. Follow best practices to ensure that search engine bots can crawl and index your site effectively.
Best practices for robots.txt optimisation
Optimising your website’s robots.txt file involves following best practices to ensure that search engine bots can access and understand your site’s content. Here are some recommended best practices:
- Allow all search engine bots: Instead of specifying a particular search engine bot, use the “*” wildcard to allow access to all bots. This ensures that your website is accessible to all search engines and not just a few.
- Disallow irrelevant directories: Identify and disallow directories that contain irrelevant or low-quality content. This helps search engines focus on crawling and indexing the most important pages on your site.
- Use comments: Adding comments in your robots.txt file can help you and others understand the purpose and structure of the file. Comments start with the “#” symbol and are ignored by search engine bots.
- Utilize the crawl-delay directive: If your website experiences high server load or bandwidth issues, you can use the crawl-delay directive to specify the time delay between subsequent crawls by search engine bots.
By following these best practices, you can optimise your robots.txt file for technical SEO and ensure that search engine bots crawl and index your website effectively.
Need a SEO specialist?

Hi, I am Max from Vizzzible. Do you want to get started with SEO, but don’t know how and where?


SEO blog topics
More blogposts like this one
- Max Schwertl
- Max Schwertl
- Max Schwertl
- Max Schwertl
- Max Schwertl
